
Conditioning Gaussian Measure on Hilbert Space
For a Gaussian measure on a separable Hilbert space with covariance operator C, we show that the family of conditional measures associated with conditioning on a closed subspace S⊥ are Gaussian with covariance operator the short S(C) of the operator C to S. Although the shorted operator is a well-known generalization of the Schur complement, this fundamental generalization to infinite dimensions of the well-known relationship between the Schur complement and the covariance operator of the conditioned Gaussian measure is new. Moreover, the conditioning of infinite dimensional Gaussian measures appears in many fields so that this simply expressed result appears to unify and simplify these efforts.
We provide two proofs. The first uses the theory of Gaussian Hilbert spaces and a characterization of the shorted operator by Andersen and Trapp. The second uses recent developments by Corach, Maestripieri and Stojanoff on the relationship between the shorted operator and C-symmetric projections onto S⊥. To obtain the assertion when such projections do not exist, we develop an approximation result for the shorted operator by showing, for any positive operator A, how to construct a sequence of approximating operators An which possess An-symmetric oblique projections onto S⊥ such that the sequence of shorted operators S(An) converges to S(A) in the weak operator topology. This result combined with the martingale convergence of random variables associated with the corresponding approximations Cn establishes the main assertion in general. Moreover, it in turn strengthens the approximation theorem for shorted operator when the operator is trace class; then the sequence of shorted operators S(An) converges to S(A) in trace norm.
Keywords:Conditioning; Gaussian Measure; Hilbert Space; Shorted Operator; Schur; Oblique Projection; Infinite Dimensions
AMS subject classifications:60B05, 65D15
For a Gaussian measure μ with injective covariance operator C on a direct sum of finite dimensional Hilbert spaces 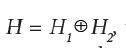 , the conditional measure associated with conditioning on the value of H2 can be computed in terms of the Schur complement corresponding to the partitioning of the covariance matrix C. Evidently, the natural extension to infinite dimensions of the Schur complement is the shorted operator, first discovered by Krein and developed in Anderson and Trapp [1,2]. However, the connection between the shorted operator and the covariance operator of the conditional Gaussian measure on an infinite dimensional Hilbert space appears yet to be established. Indeed, Lemma 4.3 of Hairer, Stuart, Voss, and Wiber, see also Stuart, characterizes the conditional measure through a measurable extension result of Dalecky and Fomin of an operator defined on the CameronMartin reproducing kernel Hilbert space [3-5]. For other representations, see Mandelbaum, and Tarieladze and Vakhania’s extension of the optimal linear approximation results of Lee and Wasilkowski from finite to infinite rank, extending results in the Information-Based Complexity of Traub, Wasilkowski and Wozniakowski [6-10].
, the conditional measure associated with conditioning on the value of H2 can be computed in terms of the Schur complement corresponding to the partitioning of the covariance matrix C. Evidently, the natural extension to infinite dimensions of the Schur complement is the shorted operator, first discovered by Krein and developed in Anderson and Trapp [1,2]. However, the connection between the shorted operator and the covariance operator of the conditional Gaussian measure on an infinite dimensional Hilbert space appears yet to be established. Indeed, Lemma 4.3 of Hairer, Stuart, Voss, and Wiber, see also Stuart, characterizes the conditional measure through a measurable extension result of Dalecky and Fomin of an operator defined on the CameronMartin reproducing kernel Hilbert space [3-5]. For other representations, see Mandelbaum, and Tarieladze and Vakhania’s extension of the optimal linear approximation results of Lee and Wasilkowski from finite to infinite rank, extending results in the Information-Based Complexity of Traub, Wasilkowski and Wozniakowski [6-10].
The primary purpose of this paper is to demonstrate that, for a Gaussian measure with covariance operator C, the covariance operator of the Gaussian measure obtained by conditioning on a subspace is the short of C to the orthogonal complement of that subspace. We provide two distinct proofs. The first uses the theory of Gaussian Hilbert spaces and a characterization of the shorted operator by Andersen and Trapp. The second proof, corresponding to the secondary purpose of this paper, uses recent developments by Corach, Maestripieri and Stojanoff on the relationship between the shorted operator and A-symmetric oblique projections. This latter approach has the advantage that it facilitates a general approximation technique that not only can be used to approximate the covariance operator but the conditional expectation operator. This is accomplished through the development of an approximation theory for the shorted operator in terms of oblique projections followed by an application of the martingale convergence theorem. Although the proofs are not fundamentally difficult, the result (which appears to have been missed in the literature) provides a simple characterization of the conditional measure, leading to significant approximation results. For instance, the attainment of the main result through the martingale approach feeds back a strengthening of the approximation theorem for the shorted operator that was developed for that purpose: when the operator is trace class the approximation improves from weak convergence to convergence in trace norm.
Conditioning Gaussian measures has applications in Information-Based Complexity and, beginning with Poincare, publications by e.g. Diaconis, Sul’din, Larkin, Sard, Kimeldorf and Wahba, Shaw, and Hagan they have been useful in the development of statistical approaches to numerical analysis [10-18]. Although they received little attention in the past, the possibilities offered by combining numerical uncertainties/errors with model uncertainties/errors are stimulating the reemergence of such methods and, as discussed in Briol et al. and Owhadi and Scovel, the process of conditioning on closed subspaces is of direct interest to the reemerging field of Probabilistic Numerics where solutions of PDEs and ODEs are randomized and numerical errors are interpreted in a Bayesian framework as posterior distributions [19-31] Furthermore, as shown in Gaussian measures are a class of optimal measures for minmax recovery problems emerging in Numerical Analysis (when quadratic norms are used to define relative errors) and conditioning such measures on finite-dimensional linear projections lead to the identification of scalable algorithms for a wide range of operators[20,32]. Representing the process of conditioning Gaussian measures on closed (possibility infinite dimensional) subspaces via converging sequences of shorted operators, could be used as a tool for reducing/compressing infinite-dimensional operators and identifying reduced models. In particular, it is shown in that the underlying connection with Schur complements can be exploited to invert and compress dense kernel matrices appearing in Machine Learning and Probabilistic Numerics in near linear complexity, thereby opening the complexity bottleneck of kernel methods [31].
Let us review the basic results on Gaussian measures on Hilbert space. A measure μ on a Hilbert space H is said to be Gaussian if, for each h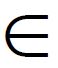 H considered as a continuous linear function h: H →R by
H considered as a continuous linear function h: H →R by 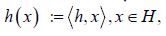 we have that the pushforward measure h*μ is Gaussian, where we say that a Dirac measure is Gaussian. For a Gaussian measure μ, its mean m is defined by
we have that the pushforward measure h*μ is Gaussian, where we say that a Dirac measure is Gaussian. For a Gaussian measure μ, its mean m is defined by
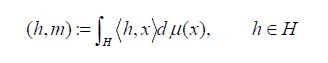
and its covariance operator C : H →H is defined by
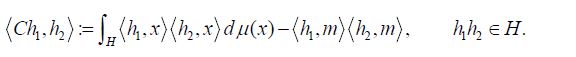
A Gaussian measure has a well defined mean and a continuous covariance operator, see e.g. Da Prato and Zabczyk [33]. Mourier’s Theorem, see Vakhania, Tarieladze and Chobanyan, asserts, for any mH and any positive symmetric trace class operator C, that there exists a Gaussian measure with mean m and covariance operator C, and that all Gaussian measures have a well defined mean and positive trace class covariance operator. This characterization also follows from Sazonov’s Theorem [34].
Since separable Hilbert spaces are Polish, it follows from the product space version, see e.g. Dudley, of the theorem on the existence and uniqueness of regular conditional probabilities on Polish spaces, that any Gaussian measure μ on a direct sum of separable Hilbert spaces has a regular conditional probability, that is there is a family μt , tH2 of conditional measures corresponding to conditioning on H2. Moreover, Tarieladze and Vakhania demonstrate that the corresponding family of conditional measures are Gaussian[8,35]. Bogachev’s theorem of normal correlation of Hilbert space valued Gaussian random variables shows that if two Gaussian random vectors ξ and η on a separable Hilbert space H are jointly Gaussian in the product space, then E[ξ|η] is a Gaussian random vector and ξ =E[ξ|η]+ζ where ζ is Gaussian random vector which is independent of η. Consequently, for any two vectors h1,h2H we have
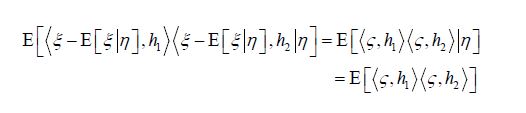
and so we conclude that, just as in the finite dimensional case, the conditional covariance operators are independent of the values of the conditioning variables [36].
Since both proof techniques will utilize the characterization of conditional expectation as orthogonal projection, we introduce these notions now. Consider the Lebesgue Bochner space L2 (H,μ,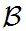 (H)) space of (equivalence classes) of H-valued Borel measurable functions on H whose squared norm
(H)) space of (equivalence classes) of H-valued Borel measurable functions on H whose squared norm
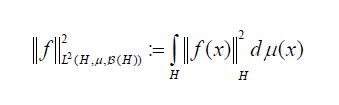
is integrable. For a sub σ-algebra 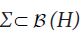 of the Borel σ-algebra, consider the corresponding Lebesgue-Bochner space L2(H,μ,Σ). As in the scalar case, one can show that
of the Borel σ-algebra, consider the corresponding Lebesgue-Bochner space L2(H,μ,Σ). As in the scalar case, one can show that 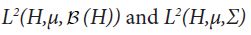 are Hilbert spaces and that
are Hilbert spaces and that 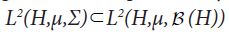 is a closed subspace. Then, if we note that contractive projections on Hilbert space are orthogonal, it follows from Diestel and Uhl that conditional expectation amounts to orthogonal projection [37].
is a closed subspace. Then, if we note that contractive projections on Hilbert space are orthogonal, it follows from Diestel and Uhl that conditional expectation amounts to orthogonal projection [37].
A symmetric operator A: H →H is called positive if(Ax,x)≥0 for all x∈H. We denote by L+(H) the set of positive operators and we denote such positivity by A≥0. Positivity induces the (Loewner) partial order ≥ on L+(H). For a closed subspace S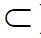 H and a positive operator A L+(H) consider the set
H and a positive operator A L+(H) consider the set
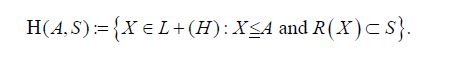
Then Krein and later Anderson and Trapp showed that H(A,S) contains a maximal element, which we denote by S(A) and call the short of A to S. For another closed subspace TH, we denote the short of A to T by T (A). In the proof, Anderson and Trapp [1] demonstrate that when A is invertible, that in terms of its (S,S⊥) partition representation [1,2].
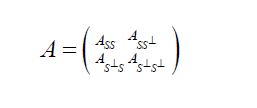
that is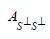 invertible and
invertible and
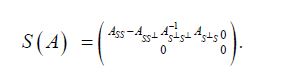
It is easy to show that the assertion holds under the weaker assumption that be invertible. Moreover, Anderson and Trapp asserts for A,B L+(H), that
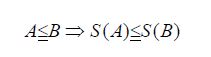
that is, S is monotone in the Loewner ordering, and for two closed subspaces S and T, we have
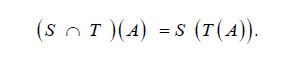
Finally, Theorem 6 of Anderson and Trapp asserts that if A: H →H is a positive operator and S⊂H is a closed linear subspace, then
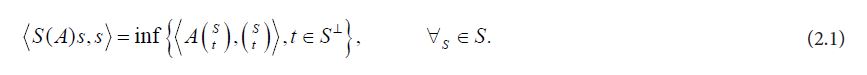
In Section 4.1 we demonstrate how the characterization (2.1) of the shorted operator combined with the theory of Gaussian Hilbert spaces provides a natural proof of our main result, the following theorem. Here we consider direct sum split and let S = H1 and S⊥ = H2, so that the short S(A) of an operator to the subspace S = H1 will be written as H1(A).
Theorem 2.1. Consider a Gaussian measure μ on an orthogonal direct sum of separable Hilbert spaces with mean m and covariance operator C. Then for all t H2, the conditional measure μt is a Gaussian measure with covariance operator H1(C).
In this section, we will prepare for an alternative proof of Theorem 2.1 using oblique projections along with the development of approximations of the covariance operator and the conditional expectation operator generated by natural sequences of oblique projections. To that end, let us introduce some notations. For a separable Hilbert space H, we denote the usual, or strong, convergence of sequences by hn →h and the weak convergence byhnω→Let L(H) denote the Banach algebra of bounded linear operators on H. For an operator A L(H), we let R(A) denote its range and ker(A) denote its nullspace. Recall the uniform operator topology on L(H) defined by the metric 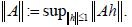 We say that a sequence of operators An L(H) converges strongly to A L(H), that is
We say that a sequence of operators An L(H) converges strongly to A L(H), that is
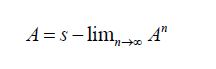
if Anh→Ah for all h∈ H, and we say that An →A weakly or
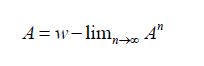
if 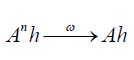 for all hH. Recall that an operator AL(H) is called trace class if the trace norm
for all hH. Recall that an operator AL(H) is called trace class if the trace norm
is finite for some orthonormal basis, where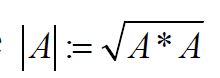 is the absolute value. When it is finite, then
is the absolute value. When it is finite, then 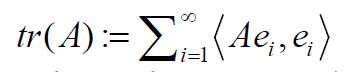 is well
defined, and for all positive trace class operators A we have 1.
is well
defined, and for all positive trace class operators A we have 1.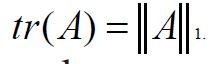 The trace norm ||.||1 makes the subspace
The trace norm ||.||1 makes the subspace 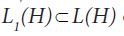 of trace class operators into a Banach space. It is well known that the sequence of operator topologies
of trace class operators into a Banach space. It is well known that the sequence of operator topologies
increases from left to right in strength.
For a positive operator A: H →H, let us define the set of (A-symmetric) oblique projections
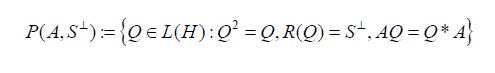
onto S⊥, where Q* is the adjoint of Q with respect to the scalar product<·,·>on H. The pair (A, S⊥) is said to be compatible, or S⊥ is said to be compatible with A, if P(A, S⊥) is nonempty. For any oblique projection QP(A, S⊥), Corach, Maestripieri and Stojanoff asserts that for E := 1−Q, we have

Moreover,when (A,S⊥) is compatible, according to Corach, Maestripieri and Stojanoff,there is a special element 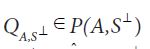 defined in the following way: by their Proposition 3.3 and their factorization Theorem 2.2 there is a unique operator
defined in the following way: by their Proposition 3.3 and their factorization Theorem 2.2 there is a unique operator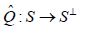 which satisfies
which satisfies 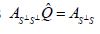 such that ker
such that ker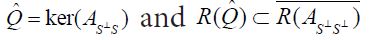 needs overbar Defining
needs overbar Defining

their Theorem 3.5 asserts that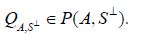
When the pair (A,S⊥) is not compatible, we seek an approximating sequence An to A which is compatible with S⊥, such that the limit of S(An) is S(A). Although Anderson and Trapp show that if An is a monotone decreasing sequence of positive operators which converge strongly to A, that the decreasing sequence of positive operators S(An) strongly converges to S(A), the approximation from above by An:=A+1/nI determines operators which are not trace class, so is not useful for the approximation problem for the covariance operators for Gaussian measures. Since the trace class operators are well approximated from below by finite rank operators one might hope to approximate A by an increasing sequence of finite rank operators. However, it is easy to see that, in general, the same convergence result does not hold for increasing sequences. The following theorem demonstrates, for any positive operator A, how to produce a sequence of positive operators An which are compatible with S⊥ such that S(An) weakly converges to S(A)[2,38].
Henceforth we consider a direct sum split , and let S = H1 and S⊥ = H2, so that the short S(A) of an operator to the subspace S = H1 will be written as H1(A). Let us also denote by Pi: H →H the orthogonal projections onto Hi, for i= 1,2, and let Πi : H →Hi denote the corresponding projections and Π*i: Hi →H, the corresponding injections. For any operator A: H→H, consider the decomposition
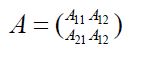
where the components are defined by Aij:=AΠ*i,i,j=1,2.
Theorem 3.1. Consider a positive operator A: H →H on a separable Hilbert space. Then for any orthogonal split and any ordered orthonormal basis of H2n,we let denote the span of the first n basis elements and let p p p denote the orthogonal projection onto Then the sequence of positive operators
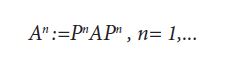
is compatible with H2 and
Remark 3.2. For an increasing sequence An of positive operators converging strongly to A, the monotonicity of the shorting operation implies that the sequence H1(An) is increasing, and therefore Vigier’s Theorem implies that the sequence H1(An) converges strongly. Although the sequence An:=PnAPn defined in Theorem 3.1 is positive and converges strongly to A, in general, it is not increasing in the Loewner order, so that Vigier’s Theorem does not apply, possibly suggesting why we only obtain convergence in the weak operator topology. With stronger assumptions on the operator A and a well chosen selection of an ordered orthonormal basis of H2, we conjecture that convergence in a stronger topology may be available. In particular, as a corollary to our main result, when A is trace class, we establish in Corollary 3.4 that
H1(An)→H1(A) in trace norm.
For any mH, we let m= (m1,m2) denote its decomposition in Moreover, for any projection Q: H →H with R(Q) = H2 we let 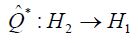 denote the unique operator such that
denote the unique operator such that
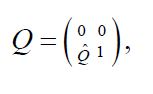
and denote by the adjoint of 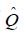 defined by the relation
defined by the relation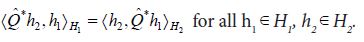
The following theorem constitutes an expansion of our main result, Theorem 2.1, to include natural approximations for the conditional covariance operator and the conditional expectation operator.
Theorem 3.3. Consider a Gaussian measure μ on an orthogonal direct sum of separable Hilbert spaces with mean m and covariance operator C. Then for all tH2,the conditional measure μt is a Gaussian measure with covariance operator H1(C).
If the covariance operator C is compatible with H2, then for any oblique projection Q in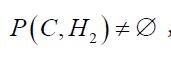 , the mean mt of the conditional measure μt is
, the mean mt of the conditional measure μt is
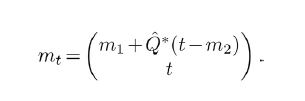
In the general case, for any ordered orthonormal basis for H2, let H2n denote the span of the first n basis elements, let p p p denote the orthogonal projection onto and define the approximate Cn:=PnCPn. Then Cn is compatible with H2 for all n, and for any sequence Qn P(Cn,H2) ≠ Ø of oblique projections, we have
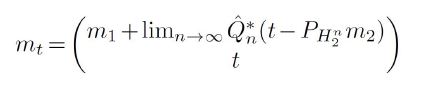
for μ-almost every t. If the sequence Qn eventually becomes the special element Qn=QCn,H2 defined near (3.2), then we have
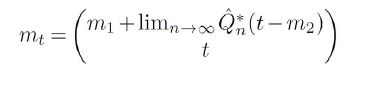
for μ-almost every t.
As a corollary to Theorem 3.3, we obtain a strengthening of the assertion of Theorem 3.1 when the operator A is trace class.
Corollary 3.4. Consider the situation of Theorem 3.1 with A trace class.Then
H1(An )→H1(A) in trace norm
First proof of Theorem 2.1 Consider the Lebesgue-Bochner space 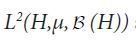 space of (equivalence classes) of H-valued Borel measurable functions on whose squared norm
space of (equivalence classes) of H-valued Borel measurable functions on whose squared norm
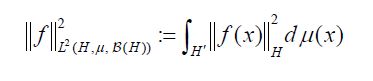
is integrable. For any square Bochner integrable function 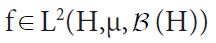 and any hH, we have that
and any hH, we have that 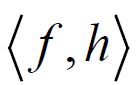 is square integrable, that is
is square integrable, that is 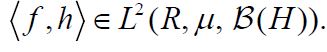 Moreover, it is easy to see that if f is Bochner integrable, then for all hH, we have is Bochner integrable and
Moreover, it is easy to see that if f is Bochner integrable, then for all hH, we have is Bochner integrable and 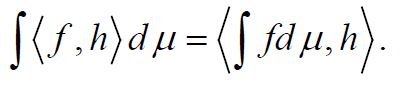
Now consider the orthogonal decomposition and the Borel σ-algebra (H2). Let us denote the shorthand notation
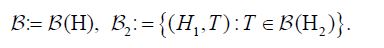
The definition of conditional expectation in Lebesgue-Bochner space, that is that 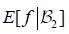 is the unique μ-almost everywhere 2-measurable function such that
is the unique μ-almost everywhere 2-measurable function such that
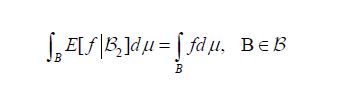
combined with Hille’s theorem [13,Thm. II.6], that for each hH we have
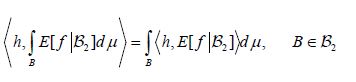
and
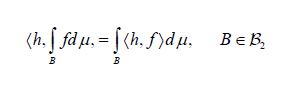
implies that
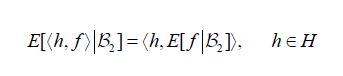
thus implying the following commutative diagram for all h H:
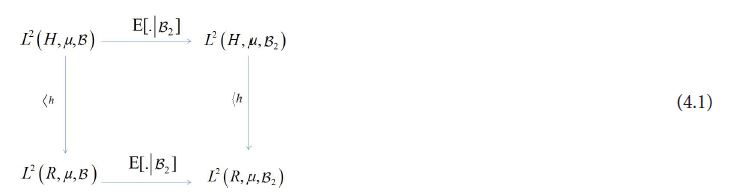
When μ is a Gaussian measure, the theory of Gaussian Hilbert spaces, see e.g. Jansen, provides a stronger characterization of conditional expectation of the canonical random variable X(h):=h,hH when conditioning on a subspace and captures the full linear nature of Gaussian conditioning [39]. Let us assume henceforth that μ is a centered Gaussian measure. Then Fernique’s Theorem, see Theorem 2.6 in Da Prato, implies that the random variable X is square Bochner integrable [33]. For any element hH, let us denote the corresponding function ξh : H →R defined by 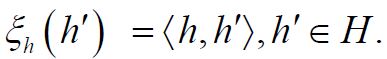 Then the the discussion above shows that for any hH, that the real-valued random variable ξh is square integrable, that is ξhL2 (R,μ,), for all hH. Let
Then the the discussion above shows that for any hH, that the real-valued random variable ξh is square integrable, that is ξhL2 (R,μ,), for all hH. Let
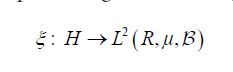
denote the resulting linear mapping defined by
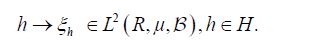
It is straightforward to show that ξ is injective if and only if the covariance operator C of the Gaussian measure μ is injective. By the definition of a centered Gaussian vector X, it follows that the law (ξh)*μ in R is a univariate centered Gaussian measure, that is ξh is a centered Gaussian real-valued random variable. Consequently, let us consider the closed linear subspace
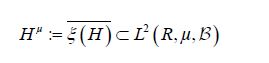
generated by the elements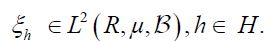 By Theorem I.1.3 of Jansen, this closure
By Theorem I.1.3 of Jansen, this closure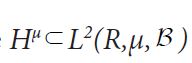 also consists of centered Gaussian random variables, and since it is a closed subspace of a Hilbert space, it is a Hilbert space and therefore a Gaussian Hilbert space as defined in Jansen [39]. Moreover, by Theorem 8.15 of Jansen, Hμ is a feature space for the Cameron-Martin reproducing kernel Hilbert space with feature map ξ: H →Hμ and reproducing kernel the covariance operator. For a closed Hilbert subspace, H2 H, we can consider the closed linear subspace
also consists of centered Gaussian random variables, and since it is a closed subspace of a Hilbert space, it is a Hilbert space and therefore a Gaussian Hilbert space as defined in Jansen [39]. Moreover, by Theorem 8.15 of Jansen, Hμ is a feature space for the Cameron-Martin reproducing kernel Hilbert space with feature map ξ: H →Hμ and reproducing kernel the covariance operator. For a closed Hilbert subspace, H2 H, we can consider the closed linear subspace
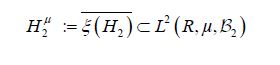
generated by the elements 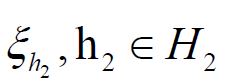 in the same way. Hμ2 is also a Gaussian Hilbert space and we have the natural subspace identification
in the same way. Hμ2 is also a Gaussian Hilbert space and we have the natural subspace identification 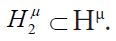 . Since separable Hilbert spaces are Polish, and an orthonormal basis is a separating set, it follows, see e.g. Vakhania, Tarieladze and Chobanyan, that for an orthonormal basis ei, iI of a separable Hilbert space, that the σ-algebra generated by the corresponding real-valued functions
. Since separable Hilbert spaces are Polish, and an orthonormal basis is a separating set, it follows, see e.g. Vakhania, Tarieladze and Chobanyan, that for an orthonormal basis ei, iI of a separable Hilbert space, that the σ-algebra generated by the corresponding real-valued functions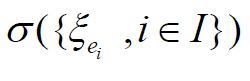 is the Borel σ-algebra of the Hilbert space. Consequently, we obtain from Janson that for any hH, that
is the Borel σ-algebra of the Hilbert space. Consequently, we obtain from Janson that for any hH, that
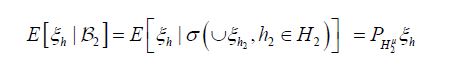
where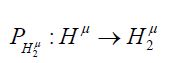 is orthogonal projection. That is, if we let
is orthogonal projection. That is, if we let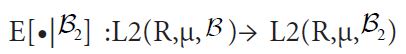 be the conditional expectation represented as orthogonal projection and
be the conditional expectation represented as orthogonal projection and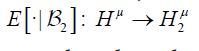 be the conditional expectation represented as orthogonal projection from the linear subspace
be the conditional expectation represented as orthogonal projection from the linear subspace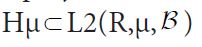 onto the closed subspace
onto the closed subspace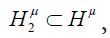 we have the following commutative diagram, where and
we have the following commutative diagram, where and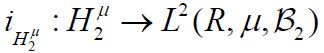 denote the closed subspace injections [34,39].
denote the closed subspace injections [34,39].
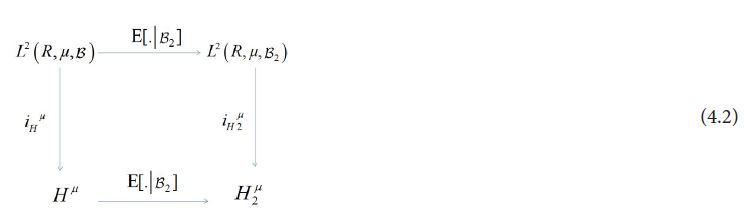
which when combined with Figure 4.1, representing the commutativity of vector projection and conditional expectation, produce the following commutative diagram for all hH:

Although there is a natural projection map PH2:H→H2 for the bottom of this diagram, in general it cannot be inserted here and maintain the commutativity of the diagram. This comes from the fact that there may exist an hH such that ξh = 0. However, this does not imply that 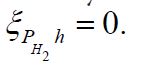 .
.
We are now prepared to obtain the main assertion. The covariance operator of the random variable X is defined by
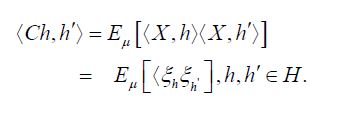
Moreover, by the theorem of normal correlation and the commutativity of the diagram (4.1), the conditional covariance operator is defined by
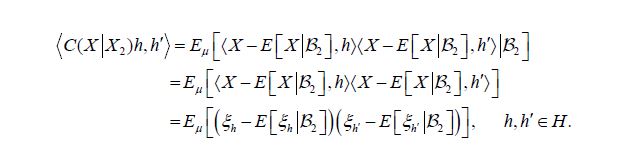
In terms of the Gaussian Hilbert spaces 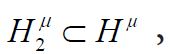 using the commutativity of the diagram (4.2) and the identification of the conditional expectation with orthogonal projection, we conclude that
using the commutativity of the diagram (4.2) and the identification of the conditional expectation with orthogonal projection, we conclude that

and
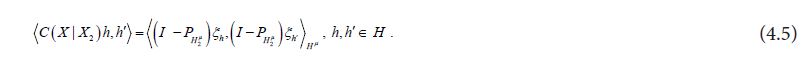
Since the orthogonal projection pHμ2 is a metric projection of Hμonto,Hμ2 we can express the dual optimization problem to the metric projection as follows: for any hH, using the decomposition h=h1 +h2 with h1H1,h2H2,we decompose 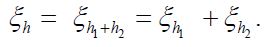 Then, noting that
Then, noting that 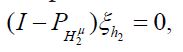 we obtain
we obtain
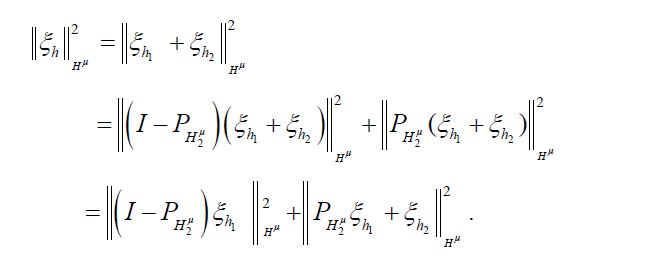
Since in the second term on the right-hand side 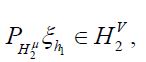 there is a sequence h2n,n=1,..... such that the corresponding sequence
there is a sequence h2n,n=1,..... such that the corresponding sequence 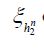 converges to
converges to 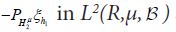 and therefore Hμ, we conclude that
and therefore Hμ, we conclude that
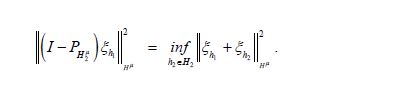
From the identifications (4.4) and (4.5), we conclude that
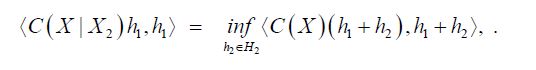
Therefore, Anderson and Trapp implies the assertion
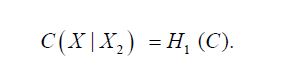
The assertion in the non-centered case follows by simple translation.
Proof of Theorem 3.1 Since 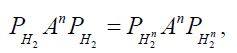 the range of
the range of 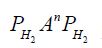 is finite dimensional, and therefore closed, so that it follows from Corach, Maestripieri and Stojanoff that An is compatible with H2 for all n. Now we utilize the approximation results of Butler and Morley for the shorted operator. By their Lemma 1, for cH and for fixed n, it follows that there exists a sequence
is finite dimensional, and therefore closed, so that it follows from Corach, Maestripieri and Stojanoff that An is compatible with H2 for all n. Now we utilize the approximation results of Butler and Morley for the shorted operator. By their Lemma 1, for cH and for fixed n, it follows that there exists a sequence 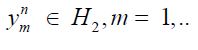 and a real number M such that
and a real number M such that
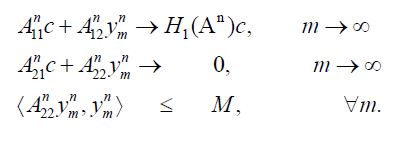
Since 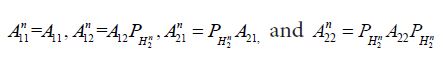 this can be written as
this can be written as
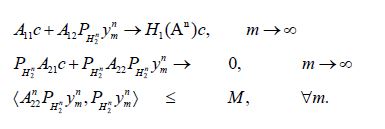
Since these equations only depend on 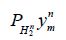 we can further assume that
we can further assume that 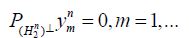 where
where 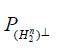 is the orthogonal projection onto
is the orthogonal projection onto 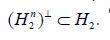 That is, we can assume that
That is, we can assume that 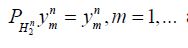 and therefore
and therefore
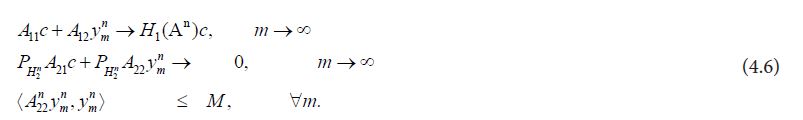
It follows from 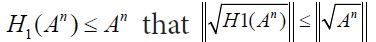 for the unique square root. Consequently, it follows that
for the unique square root. Consequently, it follows that 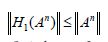 for all n and since
for all n and since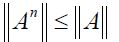 for all n it follows that
for all n it follows that 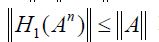 for all n. Consequently, the sequence
for all n. Consequently, the sequence 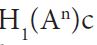 is bounded. Therefore there exists a weakly convergent subsequence. Let n′ denote the index of any weakly convergent subsequence, so that
is bounded. Therefore there exists a weakly convergent subsequence. Let n′ denote the index of any weakly convergent subsequence, so that

for some d' depending on the subsequence. Now the strong convergence of the lefthand side to the righthand side in (4.6) is maintained for the subsequence n' and, since for the subsequence the first term on the righthand side converges weakly to d′, it follows that we can define a monotonically increasing function m(n') and use it to define a new sequence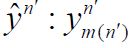 such that
such that
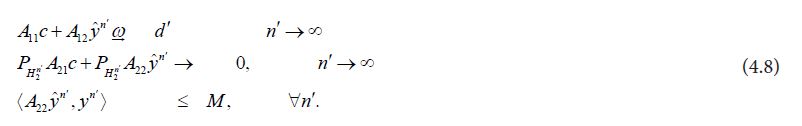
Since 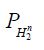 is strongly convergent to PH2 it follows that is strongly convergent to PH2 , so that
is strongly convergent to PH2 it follows that is strongly convergent to PH2 , so that 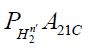 converges to
converges to 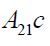 and
and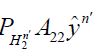 converges to -A21c Moreover, by Reid’s inequality, Corollary 2, we have
converges to -A21c Moreover, by Reid’s inequality, Corollary 2, we have

for all n',so that the sequence 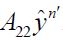 is bounded. Since weak convergence of a bounded sequence on a separable Hilbert space is equivalent to the convergence with respect to each element of any orthonormal basis, it follows that is weakly convergent to -A21c. From (4.8), we obtain
is bounded. Since weak convergence of a bounded sequence on a separable Hilbert space is equivalent to the convergence with respect to each element of any orthonormal basis, it follows that is weakly convergent to -A21c. From (4.8), we obtain

From Kakutani’s generalization of the Banach-Saks Theorem it follows that we can select a subsequence `n of n′ such that the Cesaro means of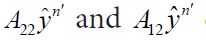 converge strongly in (4.10). That is, if we consider the Cesaro means
converge strongly in (4.10). That is, if we consider the Cesaro means
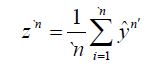
we have
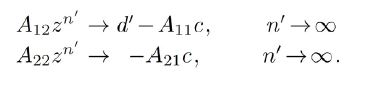
Since A22≥0 it follows that the function 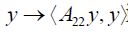 is convex, so that
is convex, so that 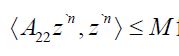 for all `n, so that
for all `n, so that
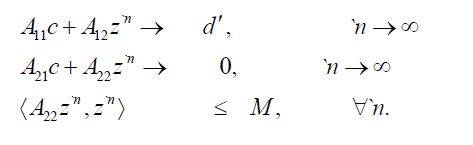
It therefore follows from Theorem 1 of Butler and Morley that
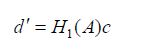
Consequently, by (4.7), we obtain that

Since this limit is independent of the chosen weakly converging subsequence, it follows that the full sequence weakly converges to the same limit, that is we have

and since c was arbitrary we conclude that
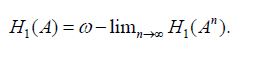
Proof of Theorem 3.3 Let us first establish the assertion when C is compatible with H2. Consider the operator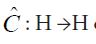 defined by
defined by

Since C is compatible with H2, there exists an oblique projection QP(C,H2), and Proposition 4.2 of Corach, Maestripieri and Stojanoff asserts that for E := 1−Q, we have

Since Q*C =CQ it follows that E*C =CE, and since Q is a projection, it follows that QE =EQ= 0 and that E is a projection. Moreover, since R(Q) = H2 it follows that ker(E) = H2, so that we obtain P2Q=Q and EP1 =E and therefore Q*P2 =Q* and P1E* =E* . Consequently, we obtain
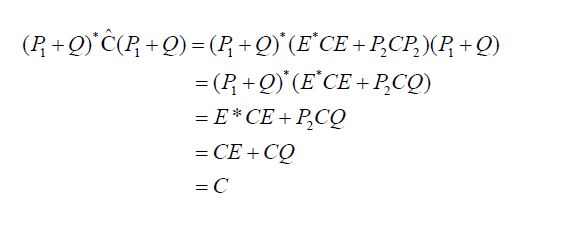

Since Q is a projection onto H2, it follows that P1+Q is lower triangular in its partitioned representation and therefore the fundamental pivot produces an explicit, and most importantly continuous, inverse. Indeed, if we use the partition representation
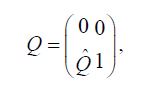
we see that
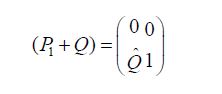
from which we conclude that
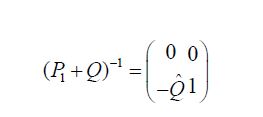
Without partitioning, using P1Q= 0 and QP2 =P2, we obtain
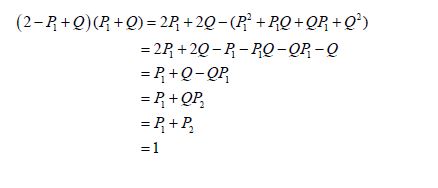
and so confirm that

Following the proof of Lemma 4.3 of Hairer, Stuart, Voss, and Wiber, let N (m,C) denote the Gaussian measure with mean m and covariance operator C and consider the transformation
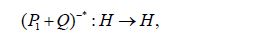
where we use the notation A−* for (A−1 )* = (A*)−1 . From (4.14) we obtain

so that the transformation law for Gaussian measures, see Lemma 1.2.7 of Maniglia and Rhandi, implies that
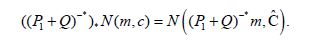
Since
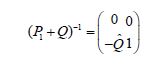
we obtain
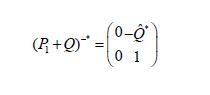
and therefore
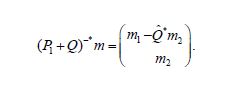
Since the partition representation of
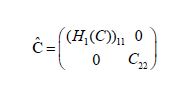
the components of the corresponding Gaussian random variable are uncorrelated and therefore independent. That is, we have
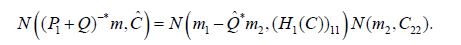
This independence facilitates the computation of the conditional measure as follows. Let X = (X1,X2) denote the random variable associated with the Gaussian measure N (m,C) and consider the transformed random variable Y = (P1+Q)−*X with the product law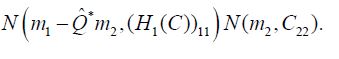 .
.
then,
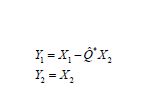
can be used to compute the conditional expectation as
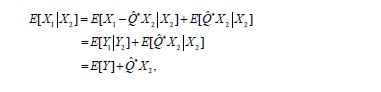
obtaining

so that we conclude that
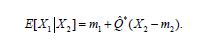
A similar calculation obtains the covariance

thus establishing the assertion in the compatible case.
For the general case, we do not assume that C is compatible with H2. Consider an ordered orthonormal basis for H2, let H2n denote the span of the first n basis elements, let  denote the orthogonal projection onto
denote the orthogonal projection onto  and consider the sequence of Gaussian measures
and consider the sequence of Gaussian measures 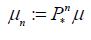 with the mean Pnm and covariance operators
with the mean Pnm and covariance operators
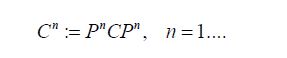
As asserted in Theorem 3.1, Cn is compatible with H2 for all n, and the sequence H1(Cn) converges weakly to H1(C). Let c(X1|H2n) and C(X1|X2) denote the conditional covariance operators associated with the measure μ. Then we will show that c(X1|H2n)=H1(cn)so that the assertion regarding the conditional covariance operators is established if we demonstrate that the sequence of conditional covariance operators c(X1|H2n) converges weakly to C(X1|X2).
To both ends, consider the Lebesgue-Bochner space L2(H,μ,) space of (equivalence classes) of H-valued Borel measurable functions on H whose squared norm
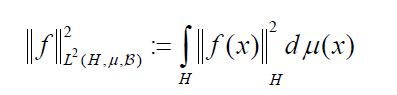
is integrable. Since Fernique’s Theorem, implies that the random variable X is square Bochner integrable, it follows that the Gaussian random variables PnX are also square Bochner integrable with respect to μ. Let us denote 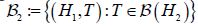 and
and 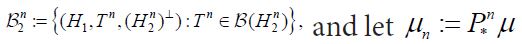 and let
and let 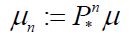 denote the image under the projection. μn is a Gaussian measure on H with mean Pnm and covariance Cn.
denote the image under the projection. μn is a Gaussian measure on H with mean Pnm and covariance Cn.
Now consider a function f: H →H which is Bochner square integrable with respect to μ and satisfies f oPn =f. Then, using the change of variables formula for Bochner integrals, see Theorem 2 of Bashirov, et al. along with the fact that 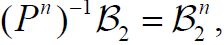 and using the fact that for an arbitrary
and using the fact that for an arbitrary 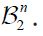 measurable function g we have g =goPn, it follows that for
measurable function g we have g =goPn, it follows that for 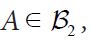 we have
we have
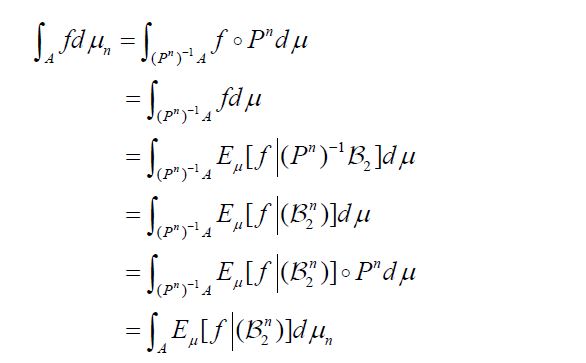
we obtain

and conclude that the sequence 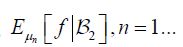 is a martingale corresponding to the increasing family of σ-algebras . Moreover, it is easy to see that (4.19) holds for real valued functions f: H →R which are square integrable with respect to μ and satisfy f foPn =f. With the choice f:= X1, we clearly have X1oPn = X1, so that if we denote X2n:=PnX2 we conclude that the sequence
is a martingale corresponding to the increasing family of σ-algebras . Moreover, it is easy to see that (4.19) holds for real valued functions f: H →R which are square integrable with respect to μ and satisfy f foPn =f. With the choice f:= X1, we clearly have X1oPn = X1, so that if we denote X2n:=PnX2 we conclude that the sequence

is a martingale. Since conditional expectation is a contraction, it follows that the L2 norm of all the conditional expectations are uniformly bounded by the L2 norm of X. Then by the Martingale Convergence Theorem, Corollary V.2.2 of Diestel and Uhl, 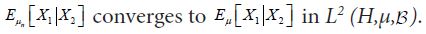 For the conditional covariance operators, observe that (4.20) implies that
For the conditional covariance operators, observe that (4.20) implies that

for all n, so that for h1,h2 H, we have
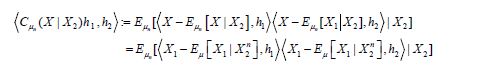
and since the integrand 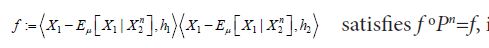 it follows from (4.19) that
it follows from (4.19) that
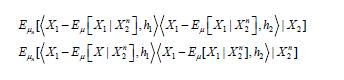
so that using the theorem of normal correlation, we obtain
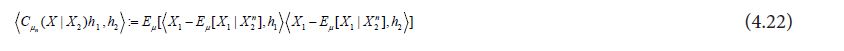
Since the theorem of normal correlation also shows that
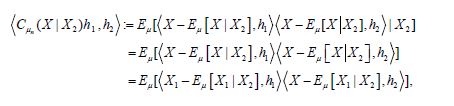
the difference in the covariances can be decomposed as
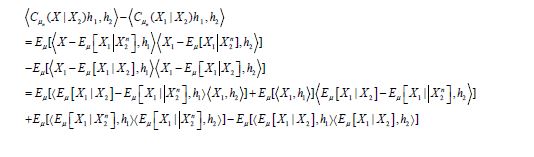
where the last term can be decomposed as
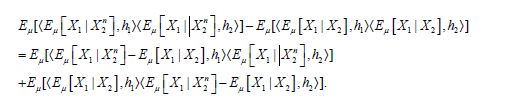
Then since conditional expectation is a contraction on L2(H,μ, ) it follows that
) it follows that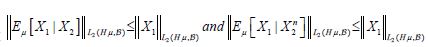 for all n. Moreover, since
for all n. Moreover, since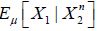 converges
converges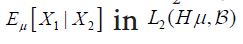 it follows that
it follows that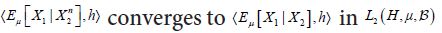 for all hH. Therefore, the Cauchy-Schwartz inequality applied four times in the above decomposition implies that
for all hH. Therefore, the Cauchy-Schwartz inequality applied four times in the above decomposition implies that
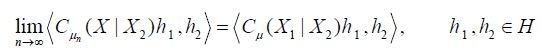
so that we obtain
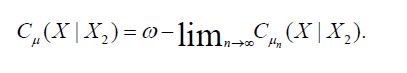
Since Cn is compatible with H2 for all n, and the compatible case demonstrated in (4.18) that

for all n, and Theorem 3.1 asserts that
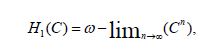
we conclude that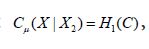 establishing the assertion regarding the covariance operators.
establishing the assertion regarding the covariance operators.
For the means, observe that since μ is a probability measure, it follows that X and therefore X1lie in the Lebesgue-Bochner space L1(H,μ, ), and since by Diestel and Uhl the conditional expectation operators are also contractions on L1(H,μ,) it also follows that 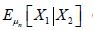 converges to Eμ[X1|X2] in L1(H,μ,). Therefore, Diestel and Uhl [13, Thm. V.2.8] implies that converges to Eμ[X1|X2] a.e.-μ. Let the conditional means Eμ[X1|X2]be denoted by Eμ[X1|X2]=mt,tH2Then, since
converges to Eμ[X1|X2] in L1(H,μ,). Therefore, Diestel and Uhl [13, Thm. V.2.8] implies that converges to Eμ[X1|X2] a.e.-μ. Let the conditional means Eμ[X1|X2]be denoted by Eμ[X1|X2]=mt,tH2Then, since
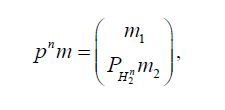
is the mean of the measure μn, the assertion in the compatible case demonstrated that the conditional means
=mtn,tH2are
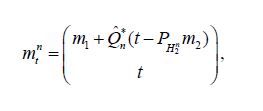
Since the conditional meansconverge to the conditional means Eμ[X1|X2]i.e.-μ amounts to mtn→mt for μ-almost every t, the first assertion regarding the means is also proved. Now suppose that Qn eventually becomes the special element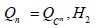 defined near (3.2). Then, by definition
defined near (3.2). Then, by definition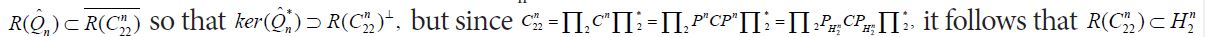 and therefore
and therefore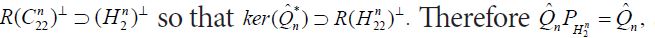 so that the final assertion follows from the previous.
so that the final assertion follows from the previous.
Proof of Corollary 3.4 By Mourier’s Theorem, there exists a Gaussian measure μ on H with mean 0 and covariance operator C :=A. Looking at the end of the proof of Theorem 3.3, since conditional expectation is a contraction on L2(H,μ,) it follows that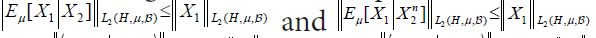 for all n. Therefore, for hH, it follows from the Cauchy-Schwartz inequality thatfor all n, uniformly for hH with ||h||H≤1Therefo the Cauchy-Schwartz inequality applied four times in the decomposition at the end of the proof of Theorem 3.3 implies that
for all n. Therefore, for hH, it follows from the Cauchy-Schwartz inequality thatfor all n, uniformly for hH with ||h||H≤1Therefo the Cauchy-Schwartz inequality applied four times in the decomposition at the end of the proof of Theorem 3.3 implies that
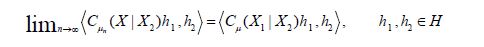
Uniformly for 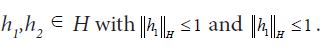 Therefore, it follows that the sequence of covariance operators converges
Therefore, it follows that the sequence of covariance operators converges
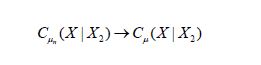
in the uniform operator topology.
According to Maniglia and Rhandi or Da Prato and Zabczyk, for a Gaussian measure μ with mean 0 and covariance operator C, we have
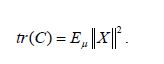
From (4.22), by shifting to the center, we obtain that
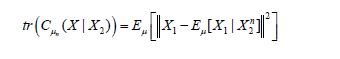
And
and therefore the difference
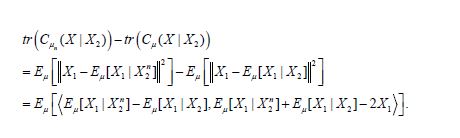
Therefore, the Cauchy-Schwartz inequality, the L2 convergence of Eμ[X1|X2n] to Eμ[X1|X2], and the uniform L2 boundedness of Eμ[X1|X2n] Eμ[X1|X2] and X1, implies that
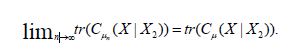
Since 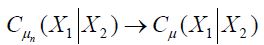 in the uniform operator topology, it follows from Kubrusly that in the trace norm topology. Since (4.23) asserts that
in the uniform operator topology, it follows from Kubrusly that in the trace norm topology. Since (4.23) asserts that 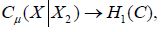 and Theorem 3.3 asserts that
and Theorem 3.3 asserts that 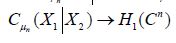 the identification A:=C completes the proof [40-46].
the identification A:=C completes the proof [40-46].
The authors gratefully acknowledge this work supported by the Air Force Office of Scientific Research under Award Number FA9550-12-1-0389 (Scientific Computation of Optimal Statistical Estimators).